
We usually train Vision-Language Models (VLMs) to give "eyes" to AI. But what if looking at pictures actually makes the model better at reading and reasoning through pure text? New research suggests that visual training is the key to breaking the "positional shortcuts" that limit Large Language Models.
A fascinating and counterintuitive phenomenon is emerging behind the scenes: VLMs can actually outperform their underlying text-only LLMs on purely textual tasks, particularly in long-context information retrieval. This raises a compelling question: Why would training an AI on images systematically improve its ability to retrieve and reason through text-only information?
Binding
Before we understand what causes this phenomenon, we need to understand the concept of “binding”.
Think of binding as a language model's ability to keep its facts straight and correctly connect the dots. If you tell a model that the square is blue and the circle is red, binding is the internal "glue" it uses to remember what color each shape is.
Basically, it’s the process of firmly linking specific attributes (like a color, a location, or a name) to their correct targets so the model can retrieve them perfectly later on. While it might sound simple, this ability to tie pieces of information together is a huge deal! It forms the bedrock of how models learn from context and is an absolute must-have before an AI can tackle any kind of complex, abstract reasoning.

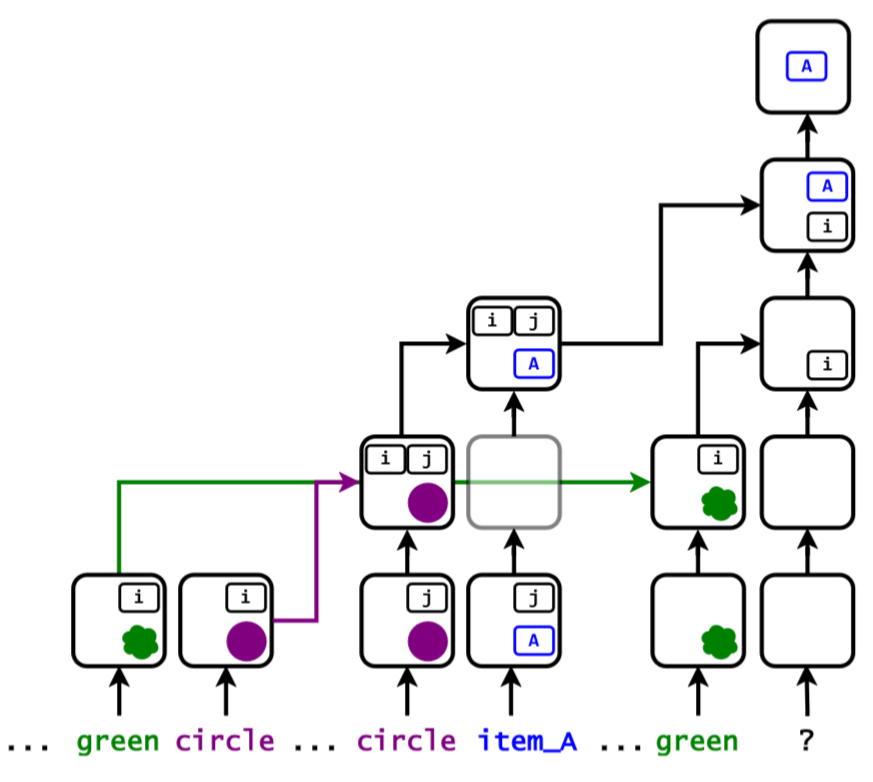
Consider the following prompt as an example. It comprises three distinct parts. First, we declare a "green circle," establishing an object with two attributes. Second, we have "circle item_A," which assigns item_A to the circle object. Finally, the last section asks the model, "what item does the green object have?"
This task requires indirect binding, where the model must connect "green circle", "circle item_A" (the item assignment), and the "green" in the question with the figure as it appears in the text. Binding is crucial for success, as the model must relate these words to correctly answer, "What item does the green object have assigned?"
The Trap of Positional Shortcuts
Now that we understand what binding means, how does this affect performance?
When a standard Large Language Model (LLM) is trained on information retrieval tasks—like matching a person to a city, or a color to a shape—it often defaults to a brittle strategy called positional binding. Instead of actually understanding the semantic link between "red" and "square," the model essentially relies on position indices . It assigns a numerical "position tag" to entities as they first appear in the prompt. For instance, if the query asks about the third color mentioned, the model simply holds onto the index "position 3". Then, it independently scans the list of associations to find the shape that points back to that exact same "position 3" index.
Within its training distribution, this position-matching shortcut works flawlessly. But when you push the model Out-Of-Distribution (OOD)—by feeding it contexts longer than it saw during training—the heuristic collapses. Unfamiliar position indices break the model's counting system, and accuracy plummets.
The Visual Cure
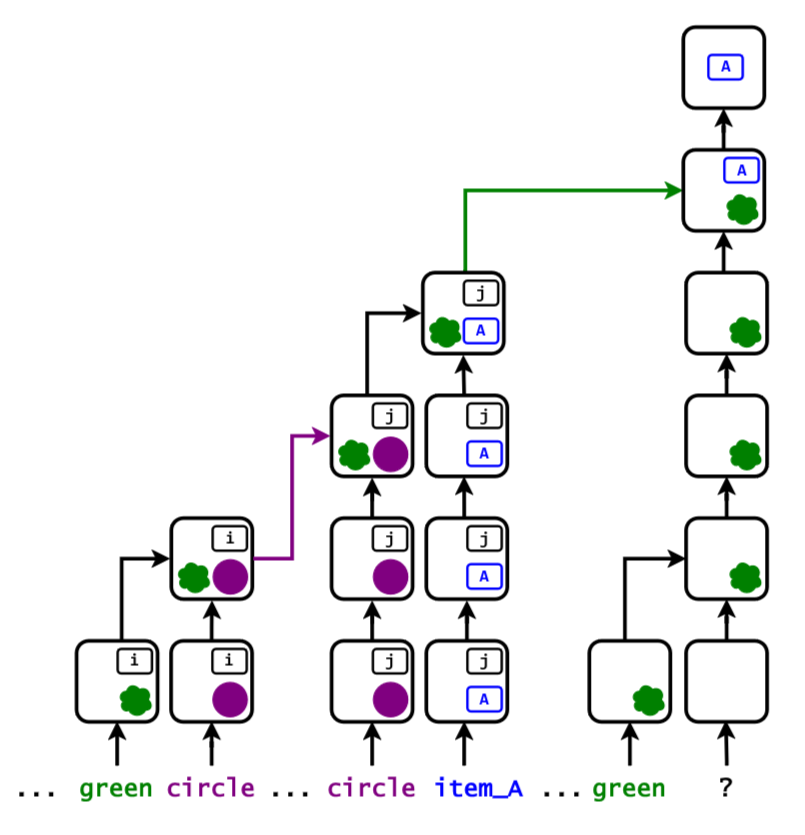
So, what happens when you introduce images?
If you take that same retrieval task and swap the text descriptions for images, the positional shortcut becomes useless. Because images possess spatial translation invariance, you can’t assign position indexes to them. In an image, what is the first object that appears? Is it the top right? Middle left? The strict, predictable ordering of text tokens is gone. Forced to adapt, the model drops its positional shortcut and adopts symbolic binding. It starts explicitly linking the semantic attributes of the objects (like their color and shape) rather than just memorizing where they appeared.
The non-obvious insight here is that this shift is permanent. When researchers reintroduced purely textual prompts to the vision-trained model, it didn't revert to cheating. It continued using the robust, symbolic binding strategy it learned from the images.
So?
You might be wondering why this matters in the real world. When you’re running these models, you don’t care how it’s solving the problem, you just care that it can solve it.
However this goes directly against the common wisdom of only choosing VLMs when you need vision capabilities. If the task you are trying to solve depends heavily on retrieval, like a RAG for example, vision-capable models might actually be better than text-only.




