
A few years ago I had an experience that completely reshaped the way I view music and technology. During Chile’s third Science Festival, I teamed up with an American musician on an ambitious experiment: to create a musical piece composed entirely by an artificial intelligence model. Our goal was to showcase a novel approach to using AI in music. We plunged into the world of generative music and developed a piece produced almost entirely by a neural network model, which was performed live by a cellist during the event.
It was an exciting project; we composed orchestrated audio with synthesizers, focused mainly on textures and atmospheres, using the concept of the Shepard tone (ascending melodies that seem never to stop rising) as input for the model.
It was a lengthy period of experimentation. The model’s unpredictability kept us fine-tuning parameters until the music achieved the coherence we wanted. After careful post-production, the project culminated in the piece below.
While this seemed innovative at the time, generative music now sits at the frontier between art and technology. Just four years later, today’s models generate sophisticated, high-fidelity compositions and offer far more intuitive workflows. Friendlier interfaces and collaborative editing let composers steer the AI and polish the output until it matches their artistic vision.
Moreover, the integration of digital post-production tools has significantly improved the quality of AI-generated audio, enabling the incorporation of both acoustic and electronic elements that enrich the final work. These advances have propelled generative music from a technical curiosity to a powerful resource for composers, producers, and artists worldwide.
Audio Music Generation
The field of AI music generation can be divided into two main directions: symbolic music generation and audio music generation. While the former focuses on creating representations of music, such as MIDI files, sheet music, or piano rolls based on musical structures and patterns, the latter dives directly into the realm of sound waves.
In audio music generation, the AI produces the raw audio signal—that is, it generates the very waveform found in a recorded track. This lets it capture essential sound nuances such as texture, timbre, and even vocal inflections—facets that symbolic generation, working with discrete data, cannot address in the same way. This approach closely resembles the recording and mixing stages of music production, enabling compositions with striking realism and sonic complexity.
One of the greatest challenges of generating music at the audio level lies in the high data rate: just a few minutes of high-fidelity audio translate into millions of sample points. Nevertheless, advances in deep learning have opened the door to this possibility, making the creation of raw audio feasible.
As we have seen, the field of AI music generation has many facets; in this article, we will focus exclusively on the approach that enables the creation of complete musical works.
How Do Generative Audio Models Work?
In the last few years, diffusion models have become the state-of-the-art technology for audio and music generation. Compared with earlier approaches—such as autoregressive models (for example, WaveNet or Jukebox) and generative adversarial networks (GANs)—diffusion models deliver unprecedented realism and audio quality, along with highly refined stylistic control. Whereas autoregressive models generate audio sequentially and GANs can struggle with stability or diversity, the diffusion methodology can create sound signals with exceptional fidelity and creative versatility.
The Diffusion Process: From Noise to Audio
The core principle behind diffusion models is to transform random noise into coherent audio through a gradual, controlled procedure. This process has two main phases:
- Forward Diffusion (noising): Noise is progressively added to an audio signal—much like the static on an old television turning a clear picture into something unrecognizable.
- Reverse Diffusion (denoising): The added noise is removed to recover (or reconstruct) the original signal. The model learns, step by step, to identify and eliminate the noise until the signal becomes a clear, well-defined piece of audio.
In essence, the process starts with white noise, which is gradually refined through successive denoising iterations. Each step brings the signal closer to a recognizable waveform, whether it’s a short sample or an entire song. This method first gained popularity in the image domain, where one can watch noise turn into a detailed picture (for example, a puppy next to a tennis ball), providing a visual demonstration of the approach’s effectiveness.

The same concept is adapted to audio. Instead of reconstructing an image, the model converts noise into a waveform that represents high-quality music or sound.

Architecture of Diffusion Models
Most diffusion models are built on the U-Net architecture, a neural network originally designed for image processing. U-Net is distinguished by a symmetric structure that combines two paths:
- Encoder (downsampling path): Captures the essential features of the audio signal. At each level the signal is compressed, allowing the model to identify global traits (such as melody and rhythm) as well as fine details (like timbral nuances).
- Decoder (upsampling path): Reconstructs the signal from the compressed representation. Skip connections between the encoder and decoder ensure that important details are preserved at every scale.
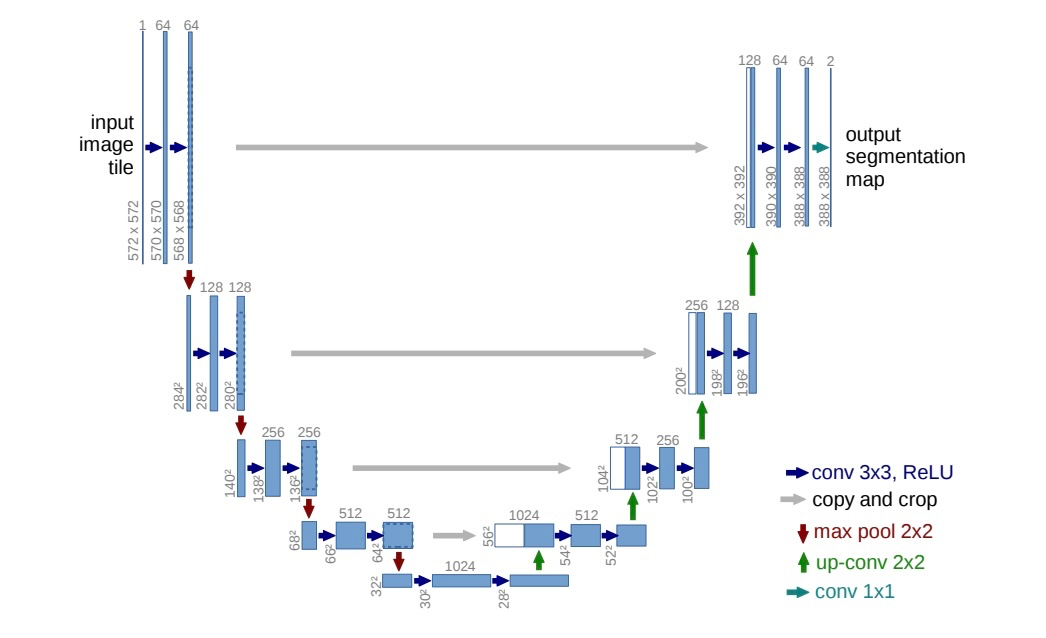
Although the original U-Net uses two-dimensional convolutions for images, it can be readily adapted to audio by switching to one-dimensional convolutions. This enables the model to learn the inherent complexity of waveforms and transform noise into coherent audio.
Training: Learning to Add and Remove Noise
A surprising aspect is that, to teach a model how to remove noise from an audio signal, it is first trained on the reverse process: adding noise. During training, the model is shown an audio signal and asked to predict that same signal with a small amount of Gaussian noise added. This noise is defined by a probabilistic distribution, allowing the model to learn predictable patterns in the signal’s corruption.
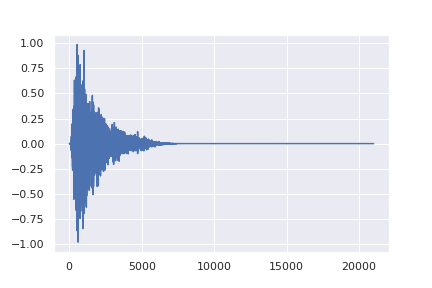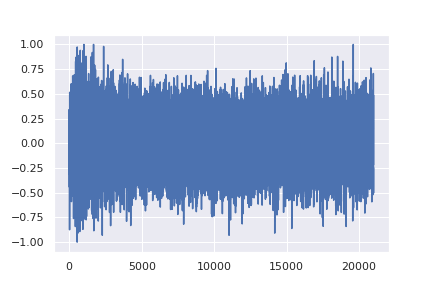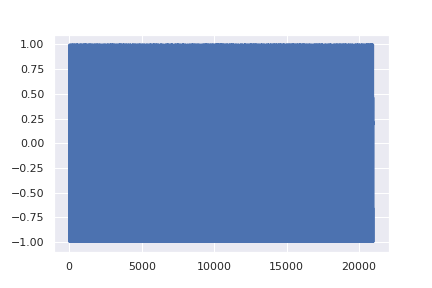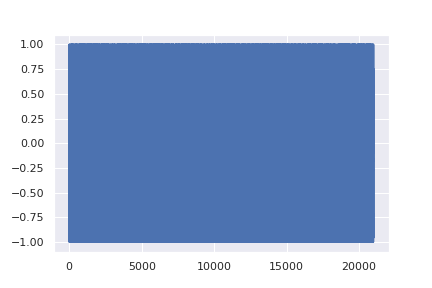
Once the model has mastered the task of injecting noise in a controlled manner, the procedure is inverted: at each iteration, part of the noise is gradually removed, refining the signal until the original audio is recovered. With a fixed number of steps (T), the model progressively transforms a fully noisy signal into a clear piece of audio, preserving both the global structure and the fine details.
Leading Music Generation Architecture
In today's landscape, numerous models can generate music with high-quality audio. However, in this section, I would like to delve deeper into what I consider the leader—and for many, one of the most outstanding developments in this field: Stable Audio. It is a latent diffusion model architecture for audio that is conditioned on text metadata as well as audio file duration and start time. This design allows precise control over both the content and the duration of the generated audio.
Stable Audio generates audio tracks in response to descriptive text prompts and a specific duration requested by the user. For example, entering a prompt like:
“Post-Rock, Guitars, Drum Kit, Bass, Strings, Euphoric, Uplifting, Moody, Flowing, Raw, Epic, Sentimental, 125 BPM”
Along with a request for a 95-second track enables the model to generate audio that adheres to both the desired style and duration (check the result here). This additional temporal conditioning overcomes a common limitation of traditional systems, which often produce fixed-size outputs and may interrupt musical phrases due to being trained on cropped segments of longer recordings.
Stable Audio Architecture
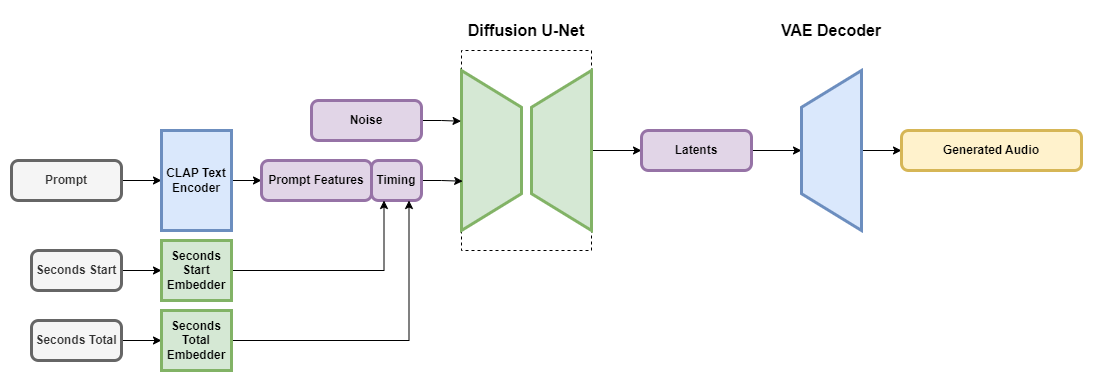
Stable Audio employs a modular latent diffusion architecture, including a Variational Autoencoder (VAE), a text encoder, and a U-Net-based diffusion model.
The VAE plays a critical role by compressing stereo audio into a data-efficient, noise-resistant, and invertible lossy latent encoding. This process facilitates faster generation and training compared to working directly with raw audio samples. The model employs a fully-convolutional architecture based on the Descript Audio Codec encoder and decoder, enabling arbitrary-length audio encoding and decoding while maintaining high-fidelity outputs.
To effectively condition the model on text prompts, a frozen text encoder from a CLAP model is utilized. This CLAP model, trained from scratch on a dedicated dataset, allows the extracted text features to capture nuanced relationships between words and sounds. These features are then supplied to the diffusion U-Net via cross-attention layers, ensuring that the generated audio accurately reflects the prompt.
During training, two key timing properties are calculated —“seconds_start” (the audio chunk's starting second) and “seconds_total” (the full duration of the original audio)— which are translated into per-second discrete learned embeddings and concatenated with the prompt tokens to guide the U-Net diffusion model via cross-attention layers. The U-Net architecture derived from Moûsai, utilizing residual, self-attention, and cross-attention layers to effectively denoise audio inputs conditioned by both textual prompts and timing embeddings, with memory-efficient attention implementations enabling scalability to longer sequences.
Evolution of Stable Audio
Stable Audio debuted in September 2023 as the first commercially viable AI music generation tool capable of producing high-quality audio at 44.1 kHz using latent diffusion technology. This release marked a milestone in the industry, earning recognition as one of TIME’s Best Inventions of 2023.
Not satisfied with this achievement, Stability AI introduced Stable Audio 2.0 in April 2024. The new version extends the model’s capabilities beyond text-to-audio conversion by incorporating audio-to-audio capabilities. Users can now upload audio samples and, through natural language prompts, transform them into a wide range of sounds. This update also enhances sound effects generation and style transfer, offering artists and musicians greater flexibility, control, and an enriched creative process.
This model is available to use for free on the Stable Audio website.
New Features
Stable Audio 2.0 significantly enhances creative tools by supporting both text-to-audio and audio-to-audio prompting. It can produce structured compositions of up to three minutes, including intros, developments, outros, and dynamic stereo effects.
Users can directly upload audio files, transforming them through natural language instructions. An integrated style transfer functionality allows further customization, matching generated or uploaded audio precisely to a project's theme and tone.
Stable Audio 2.0 Architecture
The updated architecture includes a highly efficient autoencoder that converts raw audio signals into compact latent representations, essential for handling long tracks effectively. The encoder reduces temporal resolution through strided convolutions combined with ResNet layers and Snake activations, capturing key audio elements. The decoder reconstructs the original signal using transposed convolutions, maintaining high audio quality despite compression.
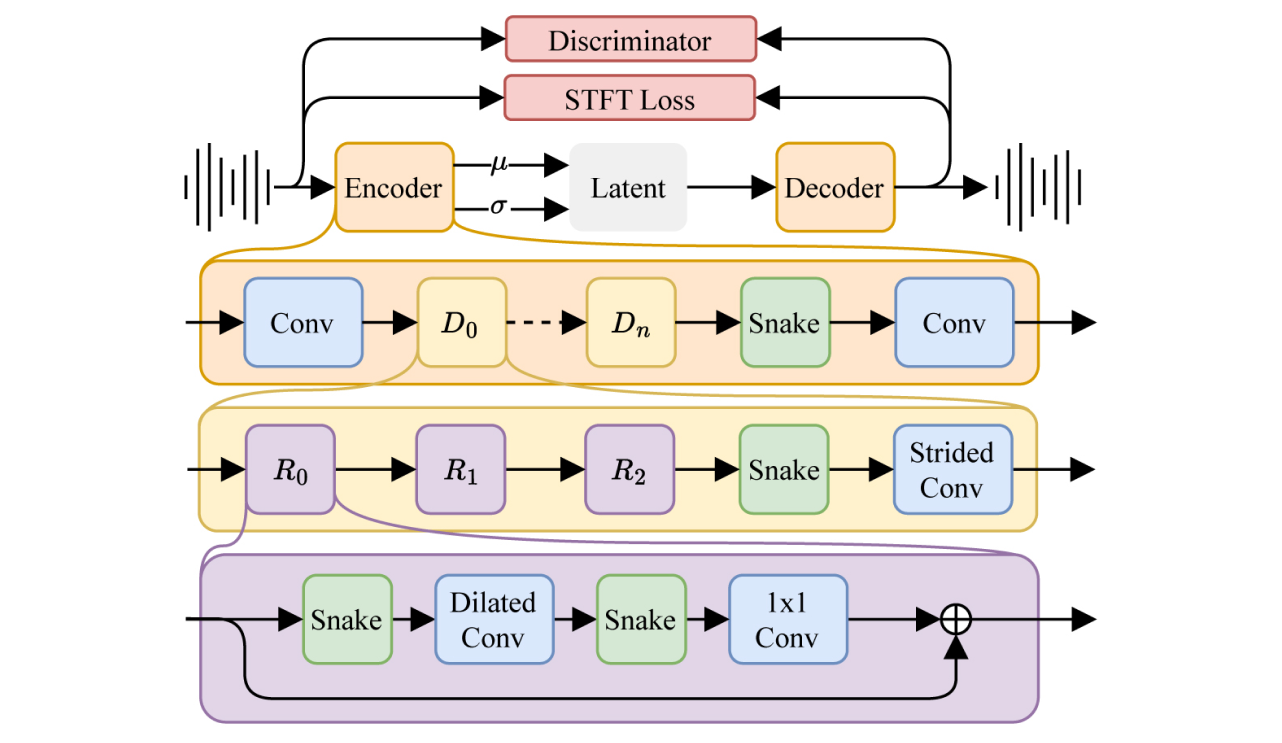
Once the compact latent representation is obtained, the next step is to apply latent diffusion via a Diffusion Transformer (DiT), which uses attention blocks and MLPs to manage longer sequences effectively. The model begins with noise in the latent space, which is refined step by step, predicting the necessary correction to gradually eliminate the noise and approach a “clean” state. Techniques such as block-wise attention and gradient checkpointing optimize computational efficiency. Conditional cross-attention layers integrate textual and timing information, ensuring coherent musical structures throughout the piece.
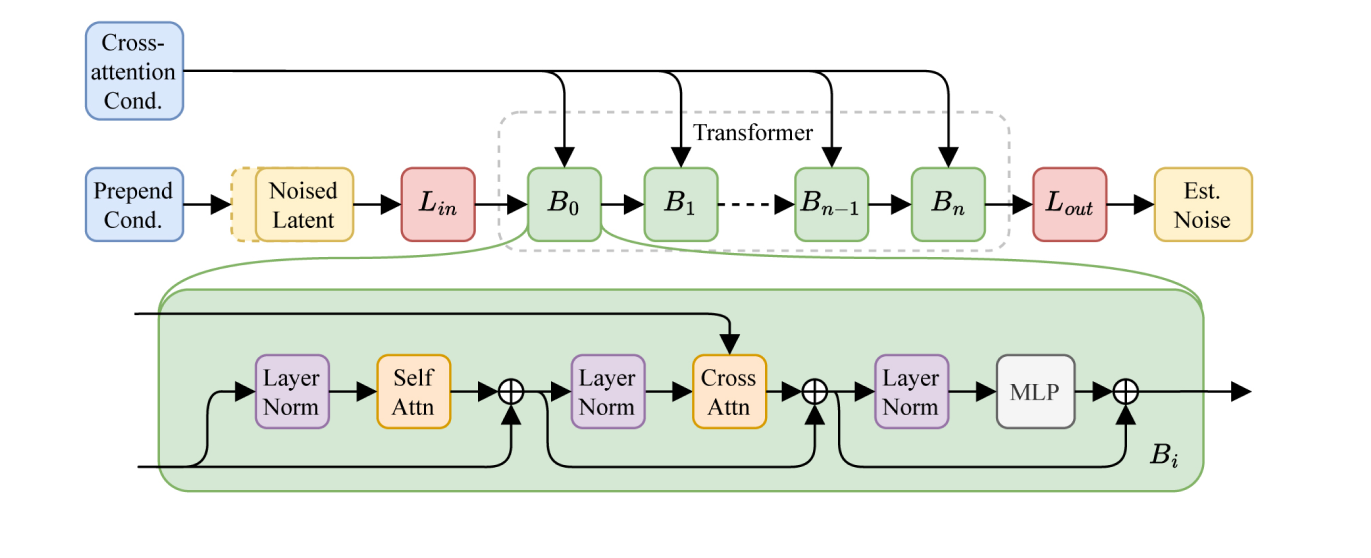
An interesting detail is that the model is prepared to generate music of different durations. A timing conditioning is introduced to indicate the model's position within the track, this enables generating various track lengths. Finally, as in its previous version, the CLAP model acts as a bridge between language and audio.
Music industry transformed by Artificial Intelligence
In recent years, AI-based music technology has advanced significantly, opening new opportunities within the commercial realm. Platforms dedicated to AI-driven music generation now offer practical and innovative solutions for producers, composers, and marketing professionals who require high-quality music but lack expertise in complex music production techniques. This democratization of AI-based music creation is not only facilitating access to professional-quality sounds but also driving commercial creativity toward previously unimaginable horizons.
AI-Generated Music Platforms for Full Tracks
Here's an overview of the latest releases of AI music generation platforms. I encourage you to visit each site and listen to other people's creations:
Stable Audio 2.0
We've already talked about its architecture, but here I'd like to go into a little detail about its platform. Stable Audio is offered via an easy web interface and an API. This model enables high-quality, full tracks with coherent musical structure up to three minutes long at 44.1 kHz stereo from a single natural language prompt. In terms of user experience, Stable Audio is prompt-driven – there’s no granular editing of the composition after generation, but you can refine the text prompts to steer the style. The system encourages iterative prompt engineering (specifying details like instruments or emotional tone) to get the best results. While it doesn’t generate vocals or lyrics, it excels at instrumental music and atmospheric soundscapes. It’s ideal for royalty-free music beds, podcasts, or video background tracks where high audio quality is needed. Stable Audio is focused on achieving high-quality audio by sacrificing functionality in its creation.
Suno – Text-to-Music with Lyrics & Vocals
Suno (v4 November 2024) is a cutting-edge AI music generator that creates full songs with vocals and lyrics from text prompts. Users can describe a genre, mood, and theme (e.g. “happy pop song about a vacation with fast piano and singing”) and Suno’s AI will compose melody, chords, beats, and even sing generated lyrics. It supports multiple languages and genres (from pop and rock to classical, jazz, etc.) and can also produce instrumental-only tracks on demand. Suno’s vocals are synthetic but surprisingly expressive, capable of rapping or singing in various styles.
Suno offers a web-based interface that’s easy for beginners. You simply type a prompt and receive two song variants (up to ~80 seconds each) within seconds. A unique feature is real-time collaboration via Discord, where users can share and co-create music live. All generated music is copyright-free and can be used in content, but commercial use requires a paid plan.
For many, Suno AI is the best music generation platform. You can read more about it in this post.
Udio – AI Song Generator with Realistic Vocals
Launched in April 2024, Udio is an AI-driven music creation platform currently in beta testing, positioning itself as a direct competitor to Suno. It allows users to generate complete songs—including instrumental compositions and emotionally expressive vocal performances—from simple or detailed prompts. Users can easily remix or expand upon the AI-generated tracks, demonstrating its flexibility and creative potential.
Udio distinguishes itself by providing diverse musical options, including custom, instrumental, and AI-generated tracks, allowing users significant creative control over lyrics and composition. Additionally, Udio clearly addresses licensing issues, guiding users regarding the commercial rights to their AI-generated content. Its standout features include high-quality vocal synthesis and genre versatility, making it appealing to creators seeking realistic and authentic AI-produced music.
Notable AI-Generated Compositions and Their Reception
To showcase how AI is reshaping the music landscape, let’s explore some prominent AI-generated compositions and examine the music industry's diverse reactions:
“Heart on My Sleeve” – Ghostwriter (Drake AI feat. The Weeknd AI, 2023)
Perhaps the most talked-about AI song of 2023, this track was created by an anonymous producer Ghostwriter977 using AI models of Drake’s and The Weeknd’s voices. The song, a catchy hip-hop/R&B number, went viral on TikTok and was briefly available on streaming platforms. Listeners were stunned at how convincingly it sounded like a collaboration between those superstars – to some, it proved that fan-made AI can rival official music in public appeal. However, the reception from the music industry was swift and negative. Universal Music Group condemned the track and pressed platforms to remove it due to copyright and impersonation issues. Within days, “Heart on My Sleeve” was taken down from Spotify, Apple Music, etc., though it still circulates online. This incident was a wake-up call: it demonstrated AI’s power to generate hit-like songs and forced the industry to grapple with managing such content. It also sparked legal discussions (as noted, via DMCA and calls for new laws). Despite the takedown, the song’s popularity (and the fact that many listeners enjoyed it before removal) showed a potential audience appetite for AI-produced novelty tracks – albeit one that clashes with current copyright frameworks.
“Now and Then” – The Beatles (2023)
In a very different scenario, AI was used by legitimate artists to create a new Beatles release. “Now and Then” was an unfinished John Lennon demo from the 1970s. In the 2020s, Paul McCartney, Ringo Starr, and the team used AI audio separation technology (developed during Peter Jackson’s Beatles documentary) to isolate Lennon’s vocal and piano from a hiss-filled tape. The cleaned-up vocals allowed the remaining Beatles to finish the production and arrangement. Released in late 2023 as “the last Beatles song,” it received a warm reception from fans and critics, largely because it authentically sounded like the Beatles and brought closure to their catalog. The use of AI here was seen as a restoration tool rather than generating something from scratch – an example of AI being used to preserve and enhance human recordings. Industry-wise, it was even nominated for a Grammy award, indicating establishment acceptance. This positive reception contrasts with the ghostwriter case: it was authorized and carefully done with respect for the artist’s legacy. “Now and Then” showed how AI can be a tool for nostalgia and preservation, extending what’s possible in music production (finishing songs that once were impossible to mix properly).
"BBL Drizzy" by King Willonius (2024)
In 2024, comedian and content creator King Willonius gained significant attention with his AI-generated song "BBL Drizzy", a parody addressing humorous rumors surrounding rapper Drake. Utilizing Udio, King Willonius crafted an R&B track stylistically reminiscent of the 1970s, combining satirical, humorous lyrics with authentic-sounding musical production.
The song rapidly went viral on platforms such as TikTok and SoundCloud, achieving millions of streams and inspiring numerous remixes across various genres. Its popularity further skyrocketed when renowned producer Metro Boomin sampled the track for an instrumental titled "BBL Drizzy," released on May 5, 2024, amid a high-profile dispute between Drake and Kendrick Lamar. This instrumental similarly went viral, attracting attention from celebrities and social media users, who produced their own versions and interpretations.
The creation and viral success of "BBL Drizzy" underscore the increasingly prominent role AI tools play in music production, illustrating how AI-generated compositions can resonate deeply and widely with global audiences while influencing popular culture.
Final Thoughts
Artificial intelligence has shifted from novelty to indispensable creative partner. Platforms like Stable Audio 2.0, Suno and Udio already act as virtual bandmates, tape-restorers and blank-canvas composers. But with this power come obligations: licensing must be ethical, attribution transparent, and artists’ voices—whether real or stylistic—respected. The wildly different reactions to “Heart on My Sleeve” and “Now and Then” prove that consent and context matter as much as audio quality.
Who “owns” an AI-generated melody, and should the data used to train these systems be disclosed—compensating the original artists in the process? As AI models grow more adept at imitating voices and styles, we must ask whether faithful reproduction crosses the line into unauthorized impersonation. Clear rules on authorship and compensation will determine whether AI becomes an ally or an ethical minefield.
For musicians, the upside is vast: faster ideation, lower barriers and entirely new genres born from human-machine synergy. Used as an instrument—not a shortcut—AI extends our imagination. Human creativity stays the melody; AI simply adds fresh harmonies and new timbres that propels the music somewhere we could never have gone alone.
References
- Landschoot, C. (2023). The State of Generative Music. Medium.
- Rouard, S., & Hadjeres, G. (2023). CRASH: Raw Audio Score-based Generative Modeling for Controllable High-resolution Drum Sound Synthesis. arXiv preprint arXiv:2402.04825.
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv preprint arXiv:1505.04597.
- Stability AI. (2023). Stable Audio: Efficient Timing Latent Diffusion.
- Stability AI. (2023). Using AI to Generate Music.
- Stability AI. (2024). Stable Audio 2.0.
- Billboard. (2024). Metro Boomin, Future and the AI Sampling Controversy Around "BBL Drizzy".
- Erdem, U. (2023). A Step-by-Step Visual Introduction to Diffusion Models.
- WandB. (2023). A Technical Guide to Diffusion Models for Audio Generation.
- Toward Data Science. (2023). Audio Diffusion: Generative Music’s Secret Sauce.
- Suno AI. (2024). Suno v4 – AI Music Generation Platform.
- Udio. (2024). AI Song Generator with Realistic Vocals.
- Ghostwriter977. (2023). Heart on My Sleeve (AI-generated track featuring Drake and The Weeknd). Viral release via TikTok.
- The Beatles. (2023). Now and Then. AI-assisted music production for official release.
- King Willonius. (2024). BBL Drizzy. AI-generated track viral on TikTok and SoundCloud, sampled by Metro Boomin.




